An interesting read was posted by a spokes person of Oxide, basically their DX12 benchmark of the Beta Ashes of the Singularity runs a notch better at specific AMD graphics cards. Is seems Nvidia is not supporting DX12 Asynchronous Compute/Shaders and actually asked the dev to disable it (content updated).
So the breaking story of the day obviously is the news that Nvidia tried to have certain features for the Oxide dev DX12 benchmark Ashes of Singularity disabled, the story continues though. The developer already posted a reply as how and what. Currently is seems that Nvidias Maxwell architecture (Series 900 cards) does not really support Asynchronous compute in DX12 at a proper hardware level. Meanwhile AMD is obviously jumping onto this a being HUGE and they quickly prepared a PDF slide presentation with their take on the importance of all this. Normally I'd share add the slides into a news item, but this is 41 page of content slides, hence I made it available as separate download.
In short, here's the thing, everybody expected NVIDIA Maxwell architecture to have full DX12 support, as it now turns out, that is not the case. AMD offers support on their Fury and Hawaii/Grenada/Tonga (GCN 1.2) architecture for DX12 asynchronous compute shaders. The rather startling news is that Nvidia's Maxwell architecture, and yeah that would be the entire 900 range does not support it in the way AMD does. I can think of numerous scenarios as to where asynchronous shaders would help.
Asynchronous shaders (async compute)
Normally with say DirectX 11 multi-threaded graphics are handled in a single queue, which is then scheduled in a set order - that's synchronously. Tasks that found themselves in different queues can now (with DX12 / Vulkan / Mantle) be scheduled independently in a prioritized order, which is asynchronous. That brings in several advantages, the biggest being less latency and thus faster rendered frames and response times while you are utilizing the GPU much better.
While this is thorny stuff to explain in a quick one page post, AMD is trying to do so (explain this) with a set of screenshots corresponding to a road with traffic lights. In the past instructions always where handled by the order that they arrived. So they arrive and get queued up. However with DX12 and the combo of GCN GPU architecture instructions can be handled and prioritized separately starting with DX12. Meaning more important tasks and data-sets can be prioritized.
With Asynchronous Shaders three different queues are now available. The graphics queue (rendering), a compute queue (physics, lighting, post-processing effects) and then there is a copy queue (data transfers). Tasks from each or any of these queues can be scheduled independently. All graphics cards based on GCN architecture can now handle multiple command instructions and data flows simultaneously which is managed by compute-engines called ACEs. Each queue can pass instructions without the need to wait on other tasks. That will keep your GPU 100% active as the work-flow is prioritized and thus always available.
Asynchronous shaders will deliver a performance increase up-to 46% in a demo shown with their LiquidVR-SDK dev kit. How big of a difference this is going to be for your 'normal' gaming experience, remains to be seen of course. But every little bump in perf is welcomed of course.
So what happened ?
NVIDIA wanted the Asynchronous Compute Shaders feature level disabled by the dev (Oxide) for their hardware as it ran worse. Even though the driver exposed it as being available. The theory right now is that NV does support it, albeit with very limited numbers
Async DX12 shader support is a uniform API level feature, part of DX12. It allows software to better distribute task intensive data. NVIDIA driver reports back that "Maxwell" GPUs supports the feature, however Oxide Games made a benchmark to showcase the power of DX 12 and ran into anomalies. When they enable async shader support the result for Maxwell based product was in their own words "unmitigated disaster". With communication back and forth with NVIDIA trying to fix things Xoide learned that "Maxwell" architecture really doesn't properly support async shaders at a tier 1 level, the NVIDIA driver might report it, but it apparently isn't working at a low-level hardware. At that stage NVIDIA started pressuring Oxide to remove parts of its code that use the feature altogether, they claim Oxide:
Oxide: Nvidia GPU's do not support DX12 Asynchronous Compute/Shaders.
The interest in this subject is higher then we thought. The primary evolution of the benchmark is for our own internal testing, so it's pretty important that it be representative of the gameplay. To keep things clean, I'm not going to make very many comments on the concept of bias and fairness, as it can completely go down a rat hole.
Certainly I could see how one might see that we are working closer with one hardware vendor then the other, but the numbers don't really bare that out. Since we've started, I think we've had about 3 site visits from NVidia, 3 from AMD, and 2 from Intel ( and 0 from Microsoft, but they never come visit anyone ;(). Nvidia was actually a far more active collaborator over the summer then AMD was, If you judged from email traffic and code-checkins, you'd draw the conclusion we were working closer with Nvidia rather than AMD wink.gif As you've pointed out, there does exist a marketing agreement between Stardock (our publisher) for Ashes with AMD. But this is typical of almost every major PC game I've ever worked on (Civ 5 had a marketing agreement with NVidia, for example). Without getting into the specifics, I believe the primary goal of AMD is to promote D3D12 titles as they have also lined up a few other D3D12 games.
If you use this metric, however, given Nvidia's promotions with Unreal (and integration with Gameworks) you'd have to say that every Unreal game is biased, not to mention virtually every game that's commonly used as a benchmark since most of them have a promotion agreement with someone. Certainly, one might argue that Unreal being an engine with many titles should give it particular weight, and I wouldn't disagree. However, Ashes is not the only game being developed with Nitrous. It is also being used in several additional titles right now, the only announced one being the Star Control reboot. (Which I am super excited about! But that's a completely other topic wink.gif).
Personally, I think one could just as easily make the claim that we were biased toward Nvidia as the only 'vendor' specific code is for Nvidia where we had to shutdown async compute. By vendor specific, I mean a case where we look at the Vendor ID and make changes to our rendering path. Curiously, their driver reported this feature was functional but attempting to use it was an unmitigated disaster in terms of performance and conformance so we shut it down on their hardware. As far as I know, Maxwell doesn't really have Async Compute so I don't know why their driver was trying to expose that. The only other thing that is different between them is that Nvidia does fall into Tier 2 class binding hardware instead of Tier 3 like AMD which requires a little bit more CPU overhead in D3D12, but I don't think it ended up being very significant. This isn't a vendor specific path, as it's responding to capabilities the driver reports.
From our perspective, one of the surprising things about the results is just how good Nvidia's DX11 perf is. But that's a very recent development, with huge CPU perf improvements over the last month. Still, DX12 CPU overhead is still far far better on Nvidia, and we haven't even tuned it as much as DX11. The other surprise is that of the min frame times having the 290X beat out the 980 Ti (as reported on Ars Techinica). Unlike DX11, minimum frame times are mostly an application controlled feature so I was expecting it to be close to identical. This would appear to be GPU side variance, rather then software variance. We'll have to dig into this one.
I suspect that one thing that is helping AMD on GPU performance is D3D12 exposes Async Compute, which D3D11 did not. Ashes uses a modest amount of it, which gave us a noticeable perf improvement. It was mostly opportunistic where we just took a few compute tasks we were already doing and made them asynchronous, Ashes really isn't a poster-child for advanced GCN features.
Our use of Async Compute, however, pales with comparisons to some of the things which the console guys are starting to do. Most of those haven't made their way to the PC yet, but I've heard of developers getting 30% GPU performance by using Async Compute. Too early to tell, of course, but it could end being pretty disruptive in a year or so as these GCN built and optimized engines start coming to the PC. I don't think Unreal titles will show this very much though, so likely we'll have to wait to see. Has anyone profiled Ark yet?
In the end, I think everyone has to give AMD alot of credit for not objecting to our collaborative effort with Nvidia even though the game had a marketing deal with them. They never once complained about it, and it certainly would have been within their right to do so. (Complain, anyway, we would have still done it, wink.gif)
--
P.S. There is no war of words between us and Nvidia. Nvidia made some incorrect statements, and at this point they will not dispute our position if you ask their PR. That is, they are not disputing anything in our blog. I believe the initial confusion was because Nvidia PR was putting pressure on us to disable certain settings in the benchmark, when we refused, I think they took it a little too personally.
AFAIK, Maxwell doesn't support Async Compute, at least not natively. We disabled it at the request of Nvidia, as it was much slower to try to use it then to not. Weather or not Async Compute is better or not is subjective, but it definitely does buy some performance on AMD's hardware. Whether it is the right architectural decision for Maxwell, or is even relevant to it's scheduler is hard to say.
Findings like these raise valid questions. Like - What does the NVIDIA driver really report? NVIDIA drivers report support DirectX 12 feature-level 12_1 in Windows, but how real is that ? It that true hardware support or as Oxide claims, semi support with a trick or two ? Meanwhile this stuff is pure gold for AMD, and they have jumped onto it as their GCN 1.1 / 1.2 architecture does support the feature properly. How important it will be in future games remains to be seen and as such is a trivial question. Regardless it's good news for AMD as it really is a pretty big DX12 API feature if you ask me. The updated slide slide deck from AMD can be download at the link below. Obviously AMD is plastering this DX12 feature level all over the web to their advantage, please do take the perf slides with a grain of salt.
Update: September 1st
some guy on Beyond3d's forums made a small DX12 benchmark. He wrote some simple code to fill up the graphics and compute queues to judge if GPU architecture could execute them asynchronously.
He generates 128 command queues and 128 command lists to send to the cards, and then executes 1-128 simultaneous command queues sequentially. If running increasing amounts of command queues causes a linear increase in time, this indicates the card doesn't process multiple queues simultaneously (doesn't support Async Shaders).
He then released an updated version with 2 command queues and 128 command lists, many users submitted their results.
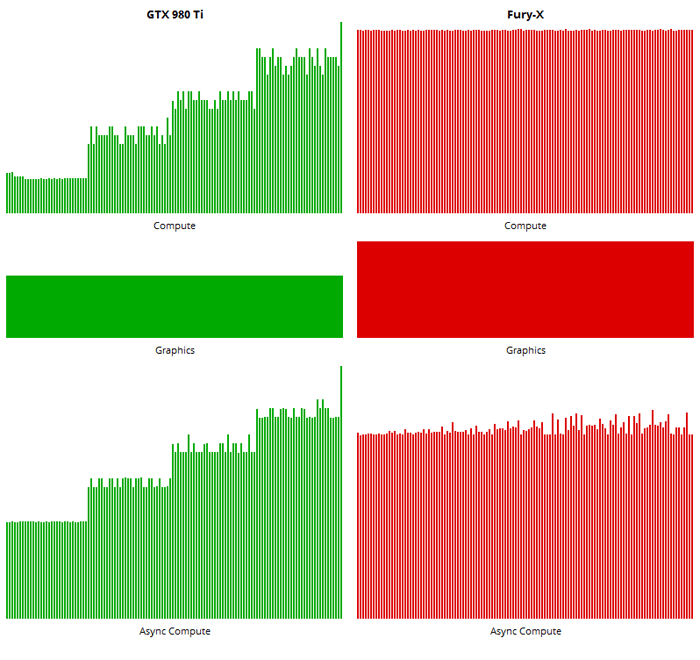
On the Maxwell architecture, up to 31 simultaneous command lists (the limit of Maxwell in graphics/compute workload) run at nearly the exact same speed - indicating Async Shader capability. Every 32 lists added would cause increasing render times, indicating the scheduler was being overloaded.
On the GCN architecture, 128 simultaneous command lists ran roughly the same, with very minor increased speeds past 64 command lists (GCN's limit) - indicating Async Shader capability. This shows the strength of AMD's ACE architecture and their scheduler.
Interestingly enough, the GTX 960 ended up having higher compute capability in this homebrew benchmark than both the R9 390x and the Fury X - but only when it was under 31 simultaneous command lists. The 980 TI had double the compute performance of either, yet only below 31 command lists. It performed roughly equal to the Fury X at up to 128 command lists.
Lower = better
Furthermore, the new beta of GameworksVR has real results showing nearly halved render times in SLI, even on the old GTX 680. 980's are reportedly lag-free now.
Well that's not proof!
I'd argue that neither is the first DX12 game, in alpha status, developed by a small studio. However, both are important data points.
Conclusion / TL;DR
Maxwell is capable of Async compute (and Async Shaders), and is actually faster when it can stay within its work order limit (1+31 queues). Though, it evens out with GCN parts toward 96-128 simultaneous command lists (3-4 work order loads). Additionally, it exposes how differently Async Shaders can perform on either architecture due to how they're compiled.
These preliminary benchmarks are NOT the end-all-be-all of GPU performance in DX12, and are interesting data points in an emerging DX12 landscape.
Caveat: I'm a third party analyzing other third party's analysis. I could be completely wrong in my assessment of other's assessments :P
Edit - Some additional info
This program is created by an amateur developer (this is literally his first DX12 program) and there is not consensus in the thread. In fact, a post points out that due to the workload (1 large enqueue operation) the GCN benches are actually running "serial" too (which could explain the strange ~40-50ms overhead on GCN for pure compute). So who knows if v2 of this test is really a good async compute test?
What it does act as, though, is a fill rate test of multiple simultaneous kernels being processed by the graphics pipeline. And the 980 TI has double the effective fill rate with graphics+compute than the Fury X at 1-31 kernel operations.
Here is an old presentation about CUDA from 2008 that discusses asynch compute in depth - slide 52 goes more into parallelism:http://www.slideshare.net/angelamm2012/nvidia-cuda-tutorialnondaapr08 And that was ancient Fermi architecture. There are now 32 warps (1+31) in Maxwell. Of particular note is how they mention running multiple kernels simultaneously, which is exactly what this little benchmark tests.
Take advantage of asynchronous kernel launches by overlapping CPU computations with kernel executions
Async compute has been a feature of CUDA/nVidia GPUs since Fermi.https://www.pgroup.com/lit/articles/insider/v2n1a5.htm
NVIDIA GPUs are programmed as a sequence of kernels. Typically, each kernel completes execution before the next kernel begins, with an implicit barrier synchronization between kernels. Kepler has support for multiple, independent kernels to execute simultaneously, but many kernels are large enough to fill the entire machine. As mentioned, the multiprocessors execute in parallel, asynchronously.
That's the very definition of async compute.
Nvidia Wanted Oxide dev DX12 benchmark to disable certain DX12 Features ? (content updated)